

软件简介
WhisperDesktop 中文汉化版 ,能够在本地电脑上将音频转换为文字。支持中文内容的转换。基于DirectCompute技术开发的AI大模型工具,运行时无需网络,不依赖除基本操作系统组件之外的任何运行时环境。处理速度远超OpenAI的实现,且内存占用低,支持多种音频和视频格式(Ogg Vorbis除外)。类似的 音视频转文字字幕工具
WhisperDesktop中文版汉化AI大模型本地音视频转文本工具 使用方法如下:
- 下载WhisperDesktop.zip和ggml语音模型文件。
- 解压WhisperDesktop.zip。
- 运行WhisperDesktop.exe,并选择要加载的语音模型。
软件支持从麦克风捕获并实时转录或翻译音频。WhisperDesktop能够实现视频和音频转文本的功能。
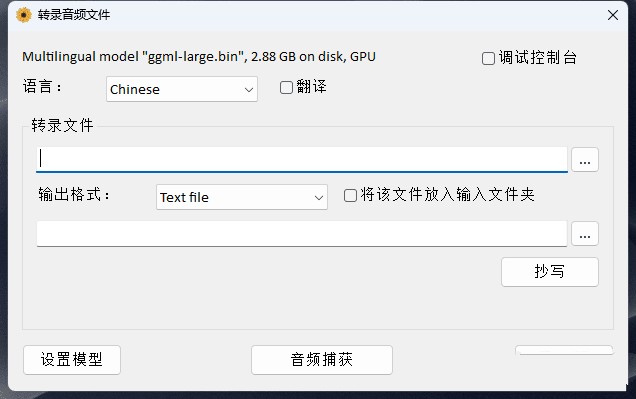
操作步骤:
- 打开软件,指定模型保存的电脑地址。
- 选择视频或音频的语言种类。
- 选择需要转换的视频或音频文件。
- 选择输出格式,如需制作视频字幕,可选subrip或webvtt格式。
- 点击转录按钮开始转换。
以一个6分41秒的视频为例,软件耗时9分41秒完成转换,英文翻译效果出色。
功能特色
- 基于 DirectCompute 的与供应商无关的 GPGPU;该技术的另一个名称是“Direct3D 11 中的计算着色器”
- 普通 C++ 实现,除基本 OS 组件外,无运行时依赖性
- 比 OpenAI 的实现快得多。
在我配备 GeForce 1080Ti GPU 的台式计算机上, 中型模型,3 分 24 秒的语音使用 PyTorch 和 CUDA 转录需要 45 秒,但使用我的实现和 DirectCompute 只需要 19 秒。
有趣的事实:这是 9.63 GB 的运行时依赖项,而不是 431 KBWhisper.dll - 混合 F16 / F32 精度:Windows 需要从 D3D 版本 10.0 开始支持缓冲区
R16_FLOAT - 内置性能分析器,可测量单个计算着色器的执行时间
- 内存使用率低
- 用于音频处理的 Media Foundation,支持大多数音频和视频格式(Ogg Vorbis 除外), 以及大多数可在 Windows 上运行的音频捕获设备(除了一些仅实现 ASIO API 的专业设备)。
- 用于音频捕获的语音活动检测。
该实现基于 Mohammad Moattar 和 Mahdi Homayoonpoor 在 2009 年发表的文章“A simple but efficient real-time voice activity detection algorithm”。 - 易于使用的 COM 风格 API。nuget 上提供的惯用 C# 包装器。
1.10 版本引入了对 PowerShell 5.1 的脚本支持,这是 Windows 上预装的较旧的“Windows PowerShell”版本。 - 提供预构建的二进制文件
GitHub开源项目地址 https://github.com/xiaoxinpro/WhisperZH